 Albresky's Blog
Albresky's Blog一种端到端半监督学习的视频动作检测算法
论文阅读笔记
一篇CVPR 2022视频动作检测论文的阅读笔记。
最近在今年的CVPR会议上看到一篇半监督的Video Action Detection算法,它首次将半监督用到动作检测方向,且性能较弱监督方法有显著提升。笔者就该文作简要分析,记录学习所得。
0 前置知识
0.1 几种监督方式的区别
0.1.1 监督学习(Supervised Learning)
已知训练集各个样本的标签,经过算法训练后的模型,可将输入数据映射到标签的过程,常用于分类问题。显而易见,有监督学习的数据标注工作的高成本的,很多任务都几乎无法获得全部真值标签的监督信息。
0.1.2 无监督学习(Unsupervised Learning)
训练集样本未被标记(无先验知识),而是通过一定的偏好对模型进行训练,最后自动地将输入数据进行分类或分群,主要运用于聚类问题、关联规则与纬度缩减。比如生成对抗网络(GAN)、自组织映射(SOM)和适应性共振理论(ART)是最常用的非监督式学习。
0.1.3 弱监督学习(Weakly Supervised Learning)
弱监督学习是相较于有监督学习和无监督学习而言的。弱监督学习并不要求所有训练数据都有真值标签或都无真值标签,而是允许一部分样本具有标签信息,因此弱监督学习是一个范围更广的概念。弱监督学习可以分为三种典型的类型:不完全监督(Incomplete supervision)、不确切监督(Inexact supervison),以及不精确监督(Inaccurate superversion)。

0.1.3.1 不完全监督(Incomplete supervision)
不完全监督主要应对只有训练集的一个很小的子集含有标签,而大量的样本为无标注的样本。如果仅仅采用有标注的信息训练模型,往往不能得到一个泛化能力强, 非常鲁棒的模型。对于不完全监督,往往有两种解决方案:主动学习(Active learning)和半监督学习(Semi-supervised learning)。
0.1.3.1.1 半监督学习(Semi-supervised learning)
让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能。
0.1.3.2 不确切监督(Inexact supervison)
不确切监督关注给定了监督信息,但是监督信息不够准确,仅仅有粗粒度的标签可用。形式化表达为,该任务是从训练数据集中学习,其中每个分子被称为一个包。每个分子的每个形状,是一个示例。以西瓜为例,好比一箩筐(包)里面装的是西瓜(示例),但是无法得知西瓜在箩筐的哪一个角落、箩筐中有多少西瓜。对于不确切监督,其解决方案主要是多示例学习(Multi-instance learning)。
0.1.3.3 不精确监督(Inaccurate superversion)
不精确监督关注的问题是对于给定的监督信息,有一些是错误的,也就是监督信息不总是ground-truth的情况。以西瓜为例,好比一箩筐带标记的西瓜中,有某些个西瓜被标注成了菠萝。该问题的解决方案是考虑带噪学习(Learning with label noise)。
0.2 Attention机制
0.2.1 为什么要引入Attention机制
在早期的机器翻译中,通常要解决不同语言的句子的翻译问题,即输入A语种的句子SA,输出翻译为B语种后的句子SB。其中最为常用的是编码-解码器(encoder——decoder)的结构,即encoder向输入读取一个句子并将其转换成一个定长向量,然后decoder将这个定长向量转换为目标语言的句子。而编解码器常采用RNN结构(如下图所示),encoder将输入的语句进行编码并传递到最后一个hidden向量中,而decoder将encoder的最后一个hidden向量作为其自身的首个hidden向量,然后decoder将向量进行解码,翻译成目标语言的语句。

但上述结构存在一个问题,即RNN机制存在长距离梯度消失的问题。随着输入语句规模的增长,最早输入的单词信息在向后传递到最后一个hidden向量时,其有效信息将大大衰减,所以对于长句子的翻译任务,RNN结构很难胜任。
0.2.2 Attention机制的解决方案

Attention机制类似于人类翻译文章的过程,即在翻译过程中,将注意力集中在当前翻译部分(原文和译文)的上下文周围。比如在翻译到“knowledge”时,只需将注意力集中在原文的“知识”周围;翻译到“power”时,只需将注意力集中在原文的“力量”和之前已经翻译过的“Knowledge is”即可。
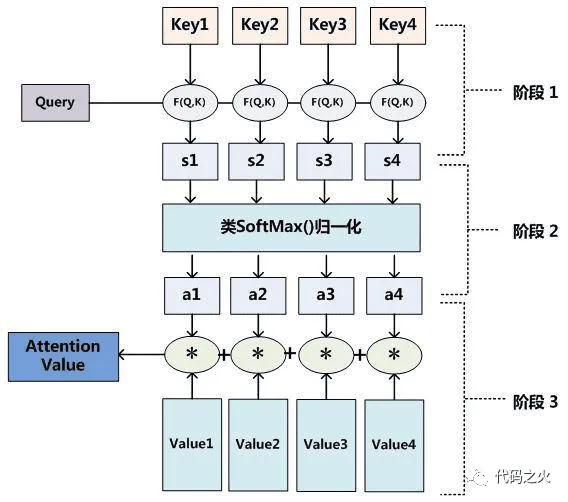
Attention操作主要分两个步骤完成。(类似于Q&A)第一步是计算Query(新Question)和memory中某个历史Key(Question)的相似度,并对这些响度度进行归一化处理作为第二步的权重系数;第二步是对于memory中所有的历史Key(Question)对应的Value(Answer)进行加权求和,加权系数即第一步中求得的归一化结果。
从本质上理解,Attention机制能够从大量信息中筛选出少量有用的重要形象,并聚焦于重要形象,同时又忽略掉大多不重要信息。聚焦体现在加权系数越大,该Value在所有Value加权求和后对结果Attention的影响越大,即权重系数反应了该信息(Value)的重要程度。
一、论文概述
1.1 概述
-
首次提出一个在视频动作检测领域的半监督算法
-
研究了两种约束条件:
- 分类一致性
- 时空一致性
-
针对时空一致性提出了两种新奇的正则化约束条件:
- 时间一致性
- 梯度平滑性
1.2 引言
视频分类任务之所以近年进展迅速,主要归功于大规模数据集的产生,而在视频中定位时空信息却是一个更具挑战的任务。除此之外,在大规模数据集上逐帧标注,显得更加履步维艰。
在论文中,作者提出了一种首次运用在视频动作检测上的方法——半监督学习。半监督学习并不陌生,但作者的这次尝试使得在小部分已标记的数据样本与大部分未标记样本组成的训练集上获得了显著成果。在图像分类和目标检测任务中,半监督学习得以成功运用,并且主要使用了伪标签(Pseudo-labeling)和一致性正则化(Consistency regularization),而伪标签依赖于多次迭代,一致性正则化依赖于逐步训练。然而这些方法都使得视频动作检测任务的计算开销更大,因此作者提出了一种基于一致性的有效解决方案。
视频动作检测依赖于样本层面(sample level)的类别预测以及逐帧的一个时空定位序列。对此,作者研究了两种使用未标记样本的一致性约束条件:分类一致性和时空一致性。Nicholas、K. Soomro等人的研究结果均表明,一致性正则化对于分类任务而言效果极佳,但它仍依赖于大规模的标注信息,因此很难在视频任务中得到表现。对此,作者提出了一个计算视频中每一像素的时空一致性的简单公式,但是将传统的一致性目标扩充到时空域,就无法捕捉到任何的时域约束条件,因为此时的一致性是独立计算每一个像素的。为了解决这个问题,作者研究了视频中的动作间存在的时间连续性,以此尝试利用这个特点来正则化时空一致性。针对上述思路,作者提出了两种捕获动作连续性的方法:时间一致性(Temporal coherence)和梯度平滑(Gradient smoothness)。时间一致性的提出主要是为了细化哪些能够确定前景和背景的不确定边界的区域,而梯度平滑则加强了时间一致性的定位。
作者提出的两种方法能够在有标签和无标签混合的样本上进行端到端的训练,并且无需任何迭代,因此计算效率极高。作者在UCF101-24和JHMDB-21上证明了这两种方法的高效:在有限标签的情况下,与全监督相比,上述方法可以取得优于所有弱监督方法的极具竞争性的性能表现。此外,作者还证明了上述方法在YouTube-VOS数据集上进行视频目标分割的泛化能力。
二、研究方法
论文作者使用了基于胶囊路由的一种端到端方法(VideoCapsuleNet)的改版架构作为动作检测的baseline网络,这种端到端方法的原版使用的是3D路由,但是其计算开销较大,论文作者将3D路由改成了2D路由,以提升计算效率。

作者提出的方法概览如下:
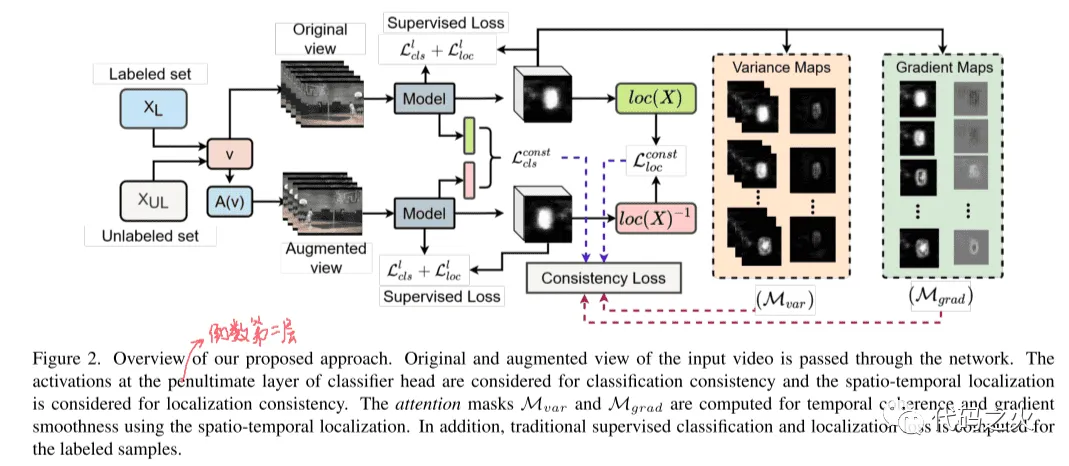
2.1 分类一致性(Classification consistency)
为了使样本和其增强视图的分类结果尽可能相似,作者以最小化样本的原始视图与其增强视图的潜在特征之间的香农散度为目标,定义了分类一致性损失函数如下:
$$ L _{c l s}^{\text {const }}= L _{J S D}=J S D\left(f e a t(X), f e a t\left(X^{\prime}\right)\right) $$
2.2 时空一致性(Spatio-temporal consistency)
在这种一致性约束条件下,动作检测网络用来学习如何检测视频在多视图下的时空定位信息l(v),对于输入的视频样本,网络会输出一个像素级别的预测定位,而每个像素都会有描述是否是某个动作的一个置信度,对于输入样本的增强视图,模型也会输出一个一致的预测结果l(v')。为了使原始视图和增强视图输出的时空定位信息尽可能相近,首先要评估原始视图和增强视图两者预测出的定位信息之间的像素差异。
为了比较上述两种视图的预测结果,作者将增强视图的数据进行了反转,以便在计算像素差异时,两种视图之间像素位置的映射是相同的。为此,利用L2范数定义了时空一致性损失函数:
$$ L _{\text {loc }}^{\text {const }}= L _{L 2}=L 2\left(\operatorname{loc}(X),\left(\operatorname{loc}\left(X^{\prime}\right)^{-1}\right)\right) $$
上式不仅捕获了不同定位图空间上的方差,而且不涉及任何时序上的约束条件,因此上式对于图像中基于一致性的目标检测任务效果甚佳。但对于视频任务而言,就有时间纬度上的必要约束,对此作者引入了连续性和平滑性的约束条件,那么这就对视频帧直接的连续性和平滑性提出了要求。
总的而言,作者为充分利用时空一致性约束条件,在探究视频中动作的时间连续性后,提出了两种时空连续性的不同研究角度:时间一致性(temporal coherence)和梯度平滑(gradient smoothness)。时间一致性关注动作在时序上相对变化的临界区域,而梯度平滑关注预测结果在时序上的突然性变化。
2.2.1 时间一致性(Temporal coherence)
时间一致性描述的是有限帧中前景像素(动作区域)在时间纬度上的相对位移。作者通过计算某一帧中所有像素点在前后帧中位置的相对变化的方差(视频的每一帧都要这么计算),来评估预测结果在短期中细粒性变化的连续程度,这些方差组成了一个方差映射$M_{var}$。
$$ M_{var}=\frac{\sum_{i=1}^n{({loc}_i-\mu_n)}^2}{n} $$
其中,$n$表示视频的总帧数,${\mu}_n$表示这$n$个帧的均值。
如 框架概览图 所示,通过分析方差映射可知,预测结果将会出现两种明显的区域:清晰的(某个像素属于某个动作)和模糊的(某个像素不属于某个动作)。而作者着重关注这些模糊的区域,因为这些模糊的区域包含了一些前景和背景的临界信息,而方差映射图则能帮助作者在模糊区域通过注意力机制(Attention)挖掘更多时空纬度的信息。
作者通过利用方差图来进行注意力操作,并以此定义时空一致性损失函数:
$$ L _{\text {var }}^{\text {const }}=\widehat{w} \cdot\left( M _{\text {var }} \odot L _{L 2}\right)+(1-w) \cdot\left( L _{L 2}\right) $$
其中$w$表示视频中每一个像素的权重,初值为$0$。
随着训练的推进,模型可以识别出粗粒度的动作定位信息,但仍存在不确定的临界区域。对此,作者对训练过程中的时间一致性的注意力mask的权重进行了指数级增长。最后,为了获得更长时间上的时间信息,作者使用了增强视图,即把增强的空间视图进行翻转,剔除首尾帧后加入原始视图,以计算长片段的方差,并将此过程描述为“循环方差(cyclic variance)”。
2.2.2 梯度平滑性(Gradient smoothness)
从时间角度看时空定位信息,定位信息的过渡应该是平滑的。为了维持这种平滑约束,作者对输出定位信息的score maps计算二阶梯度。时空定位信息的时间纬度的一阶梯度提供了一个时间上的梯度流图,由于时间维度上的便宜很小,因此一阶梯度应该也是平滑的,那么其二阶梯度应该为$0$。此时,如果二阶梯度图上出现了尖峰,那么说明梯度流图出现了连续性(continuity)的变化。作者通过$M_{grad}$作为注意力来加强时空定位的长距离平滑性。梯度平滑性的一致性损失定义如下:
$$ L _{\text {grad }}^{\text {const }}=\left( M _{\text {grad }} \odot L _{L 2}\right) $$
其中,$M_{grad}$计算如下:
$$ M_{grad} = \frac{\partial^2 \text{(loc)}}{\partial t^2} $$$$ \text{where} \frac{\partial (\text{loc})}{\partial t} = \frac{\text{loc}{t+1} - \text{loc}{t-1}}{2} $$
2.3 顶层训练目标
综合的有监督损失函数:
$$ L _{\text {labeled }}= L _{\text {cls }}^l+ L _{\text {loc }}^l $$
组合的一致性损失函数:
$$ L _{\text {const }}=\lambda_1 L _{\text {cls }}^{\text {const }}+\lambda_2\left( L _{\text {var }}^{\text {const }} / L _{\text {grad }}^{\text {const }}\right) $$
其中,${\lambda}_1$和${\lambda}_2$表示分类一致性和时空一致性的相对权重。
最终的总体训练目标损失函数:
$$ L _{\text {total }}= L _{\text {labeled }}+\lambda L _{\text {const }} $$
其中,$\lambda$表示一致性损失函数的权重。
三、实验
3.1 数据集
主要使用的UCF101-24(训练和测试样本规模大约是5比2)和JHMDB-21两个数据集,视频分辨率均为320x240。作者为了表现该模型在其他领域中的泛化能力,还在YouTube-VOS数据集上进行了测试。
3.2 实验细节
实验中,作者使用的帧分辨率是224x224,batch size为8,每一个batch中,标记样本和未标记样本的规模五五开,而每个batch分为8个视频片段,那么每个batch有4个未标记样本子集,4个有标记样本子集,每个片段又有8帧(每隔2帧采样一次),样本集在训练前被随机打乱。对于UCF101-24数据集,标记样本和未标记样本的分布为20/80,而JHMDB-21为30/70。此外,实验用I3D模型``和Kinetics以及Charades的预训练权重参数作为backbone。
3.3 评价指标
- f-mAP(frame-metric average precision)
- v-mAP(video-metric average precision)
3.4 Baselines
为了和已知方法进行比较,作者将一些半监督的图像分类的方法扩展到视频中。这些方法包括Pseudo-label,MixMatch和Consistency-based Object Detection (Co-SSD (CC))。
四、结果
4.1 两种约束条件下的性能对比
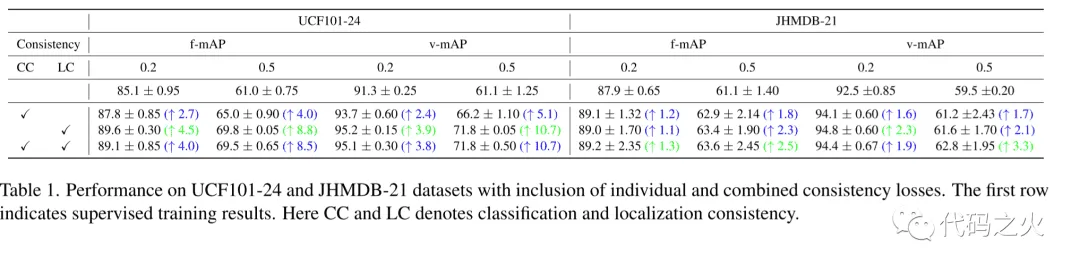
表中CC表示分类一致性、LC表示时空一致性。第一行表示有监督的性能指标,第二行表示仅分析分类一致性的性能指标,第三行表示只分析时空一致性,而第四行表示同时分析两种一致性时的性能指标。通过将仅分析LC、仅分析CC和两者都分析做对比可以发现,时空一致性约束对于模型性能提升影响更大。
4.2 半监督、弱监督及有监督学习下的性能对比
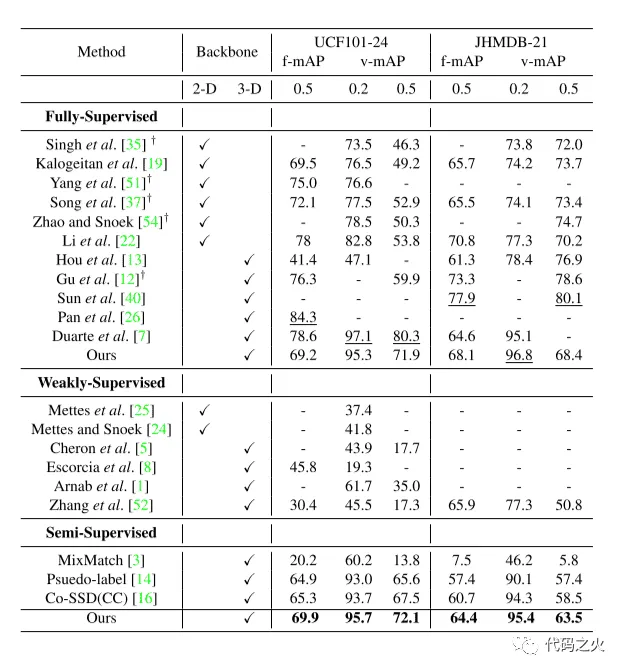
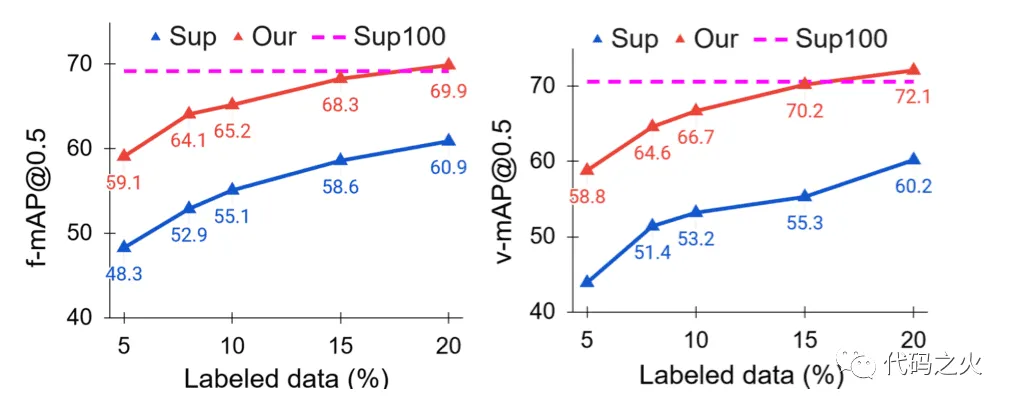
在半监督方法中,MixMatch表现最差,而论文提出的方法在半监督和所有弱监督方法中,性能表现均最好。在全监督方法中,论文的方法性能仍优于大多数。
参考
- End-to-End Semi-Supervised Learning for Video Action Detection
- 弱监督学习综述
- 浅谈弱监督学习(Weakly Supervised Learning)
-
《机器学习》(周志华)—— 第十三章 半监督学习
 支付宝
支付宝
 微信
微信